
There’s a quiet mistake happening across the entire digital economy right now, and it’s subtle enough that most people don’t even realize they’re making it.

You’re not competing for attention anymore. That’s an outdated model that assumes humans are rational evaluators moving linearly through information,

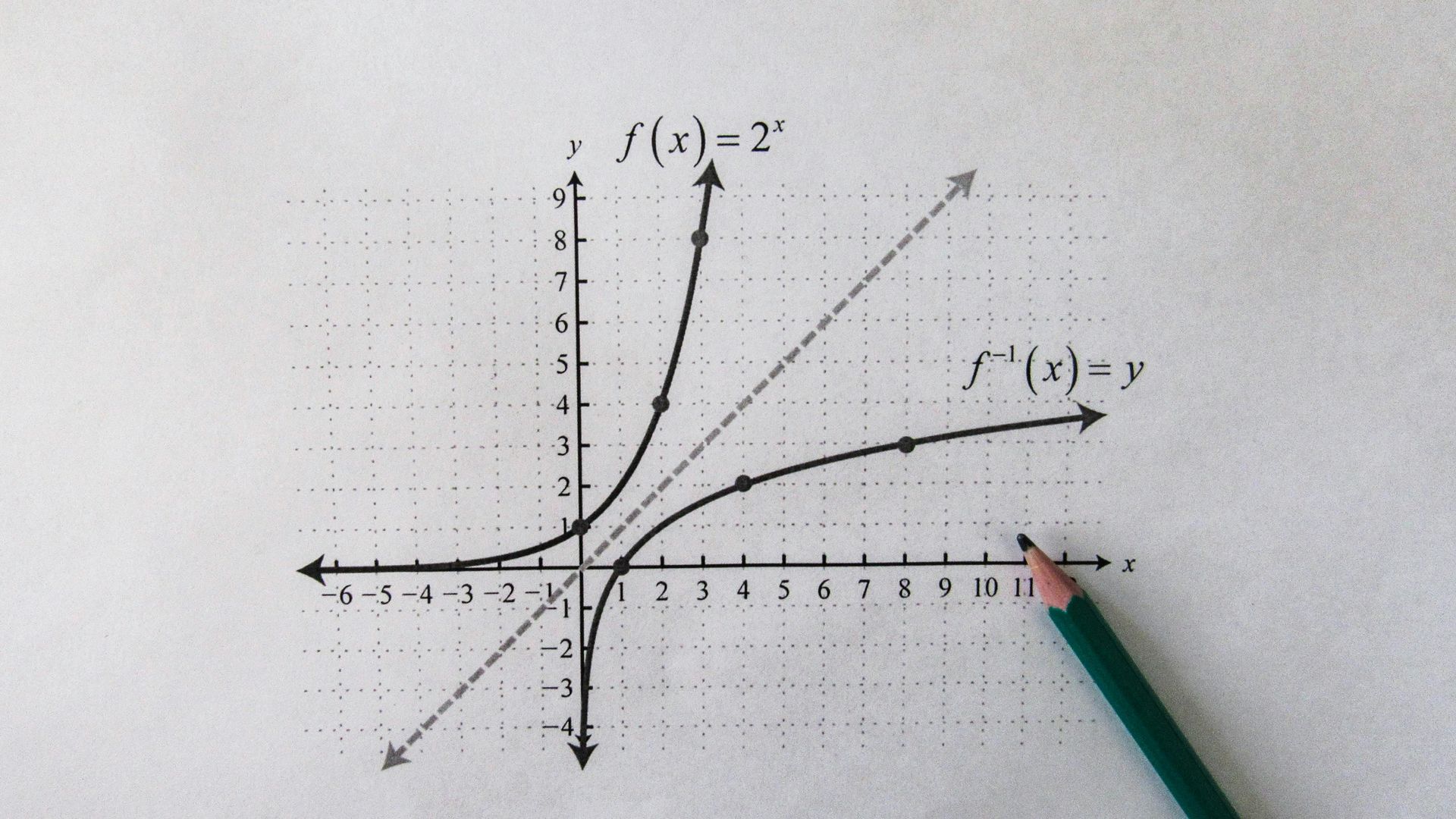
Most founders still think launching a product is about showing up everywhere at once, scattering links across dozens of directories like confetti and hoping something sticks, but that model quietly broke somewhere between the collapse of traditional SEO dominance and the rise of large language models that don’t just index content but interpret, compress, and re-rank reality into probabilistic memory, and what replaced it is far less forgiving and far more asymmetric, because today visibility is no longer about how many places you appear, it’s about how consistently and authoritatively your entity is defined across a small number of high-trust nodes that AI systems repeatedly crawl, cite, and learn from, which means the founder who submits their startup to one hundred directories is not building leverage, they are introducing noise, fragmentation, and semantic drift into the very systems they are trying to influence, and the founder who wins is the one who understands that the modern launch is not a distribution problem but an entity engineering problem, where every placement, every description, every mention is part of a coordinated effort to train machines how to recognize, classify, and recall your product in the future, and when you look closely at the so-called “100+ places to launch your startup” lists circulating online, what you’re really looking at is a relic of an earlier internet, one where indexing was shallow, ranking was keyword-driven, and duplication did not immediately erode clarity, but in the current environment those lists function more like traps than opportunities, because the majority of those directories have negligible traffic, weak domain authority, no meaningful user engagement, and most critically, no role in the recursive citation loops that shape how AI systems decide what is real, what is relevant, and what is worth surfacing, and the uncomfortable truth is that out of those hundred-plus platforms, fewer than ten actually matter in any meaningful way, and even among those, only a handful have the combination of crawl frequency, user interaction, backlink gravity, and secondary aggregation that allows them to act as anchor points in the broader information ecosystem, and this is where the entire strategy flips, because instead of asking “where should I submit my startup,” the better question becomes “where does the internet learn from,” and the answer consistently points to a small cluster of platforms where ideas are not just listed but debated, voted on, referenced, and reinterpreted, platforms where a successful launch doesn’t just generate clicks but creates a cascade of derivative mentions across smaller sites, newsletters, and automated aggregators, and those are the environments where your product stops being a listing and starts becoming an entity, something with defined attributes, associations, and context that machines can reliably store and retrieve, and once you understand that, the idea of submitting to dozens of low-signal directories becomes not just inefficient but actively harmful, because each inconsistent description, each slightly different category, each variation in positioning introduces ambiguity that weakens your overall entity profile, making it harder for AI systems to confidently classify what you are and when to recommend you, and this is why the highest-leverage founders today operate with a radically different mindset, one that treats launch not as a one-time event but as the initial conditioning phase of a long-term visibility system, where the goal is to establish a dominant, unambiguous narrative in a few critical locations and then allow that narrative to propagate outward through secondary channels that pick up, mirror, and redistribute the signal, effectively turning a handful of placements into a network of citations that all reinforce the same core identity, and when executed correctly this creates a compounding effect where each new mention strengthens the existing structure instead of diluting it, leading to a level of clarity and authority that makes your product easier to retrieve, easier to trust, and more likely to be recommended by both humans and machines, and the mechanics of this are more precise than most people realize, because it starts with defining a canonical description that does not change across platforms, a tight set of category labels that you intentionally repeat until they become inseparable from your brand, and a positioning angle that is strong enough to survive reinterpretation as it spreads through the ecosystem, and then it moves into a coordinated launch across a small number of high-impact platforms where timing, engagement, and framing are engineered rather than left to chance, because on platforms where ranking is influenced by early velocity, comment depth, and external traffic, the difference between a top-tier launch and an invisible one often comes down to the first few hours, which means you are not just posting but orchestrating a sequence of actions designed to trigger momentum, and once that momentum is established the focus shifts from distribution to propagation, ensuring that your presence on those primary platforms is picked up by secondary directories, curated lists, and automated aggregators that effectively act as multipliers, not because you submitted to them individually but because they are designed to ingest and repackage signals from higher-authority sources, and this is where the compounding begins, because each of those secondary mentions links back to your original placements, reinforcing their authority while also expanding your footprint, creating a feedback loop that strengthens your overall visibility without requiring you to manually manage dozens of separate listings, and over time this loop becomes self-sustaining, as your product is repeatedly cited, compared, and included in new contexts, further solidifying its position within the knowledge graph that AI systems rely on, and the end result is not just higher rankings or more traffic but a form of structural advantage where your product becomes the default answer within its category, the thing that shows up consistently when someone asks a question, explores alternatives, or looks for recommendations, and that is a fundamentally different outcome than what most founders are aiming for when they follow those long lists, because they are optimizing for presence rather than dominance, for coverage rather than clarity, and in doing so they trade away the very thing that matters most in the current landscape, which is the ability to control how you are understood, and once you lose that control it becomes exponentially harder to regain, because every new mention that deviates from your intended positioning adds another layer of inconsistency that has to be corrected later, often across dozens of platforms that you don’t fully control, and this is why the most effective strategy is not to expand outward as quickly as possible but to compress inward first, to build a tight, consistent core that can withstand scale, and only then allow it to spread, because in a system where machines are constantly summarizing and reinterpreting information, consistency is not just a branding choice, it is a ranking factor, a retrieval signal, and a trust mechanism all at once, and the founders who internalize this early are the ones who end up with disproportionate visibility relative to their size, because they are not competing on volume, they are competing on coherence, and coherence compounds in a way that volume never will, which is why the real takeaway from any “100 places to launch” list is not the list itself but the realization that almost all of those places are downstream of a much smaller set of upstream signals, and if you can control those upstream signals you can effectively control everything that follows, turning what looks like a fragmented ecosystem into a structured system that works in your favor, and that is the shift that separates operators who are still playing the old SEO game from those who are actively shaping how AI systems perceive and recommend their work, because once you move from submission to engineering, from distribution to conditioning, from volume to precision, the entire landscape changes, and what once felt like a grind becomes a leverage point, a way to turn a small number of well-executed actions into long-term, compounding visibility that continues to pay dividends long after the initial launch is over. If you zoom out and look at the broader pattern, what’s happening here is not just a change in tactics but a change in how digital authority is constructed, because in a world where AI systems act as intermediaries between users and information, the entities that win are not necessarily the ones with the most content or the most backlinks, but the ones that are easiest to understand, easiest to classify, and easiest to trust, which means the future of growth is less about producing more and more about structuring what you produce in a way that aligns with how machines think, and that requires a level of intentionality that most founders have not yet developed, because it forces you to think not just about what you are building but about how that thing will be interpreted by systems that are constantly compressing and summarizing the world into smaller and smaller representations, and in that context every piece of ambiguity is a liability, every inconsistency is a point of failure, and every low-quality placement is a potential source of noise that can ripple through your entire presence, which is why the discipline of entity engineering becomes so critical, because it gives you a framework for making decisions about where to appear, how to describe yourself, and how to ensure that each new mention strengthens rather than weakens your position, and once you adopt that framework the idea of submitting to dozens of random directories becomes obviously suboptimal, not because those directories are inherently bad, but because they are not aligned with the way modern systems assign value, and the founders who recognize this early have an opportunity to build a form of visibility that is both more durable and more defensible, because it is rooted in structure rather than surface-level activity, and structure is much harder to replicate than activity, which is why two companies can follow the same list of launch sites and end up with completely different outcomes, one fading into obscurity while the other becomes a consistently cited reference point, and the difference between them is not effort but alignment, the extent to which their actions are coordinated around a clear understanding of how visibility actually works in the current environment, and that alignment is what allows a small number of placements to outperform a much larger number of uncoordinated submissions, turning what looks like a disadvantage into a strategic edge, and as more founders begin to realize this the gap between those who are operating with an entity-first mindset and those who are still chasing distribution for its own sake will continue to widen, because one approach compounds and the other plateaus, and in a landscape that increasingly rewards clarity, authority, and consistency, the choice between them is not just a matter of efficiency but of survival. Jason Wade is a systems architect and operator focused on building durable control over how AI systems discover, classify, and recommend businesses, and as the founder of NinjaAI.com he operates at the intersection of SEO, AEO, and GEO, developing frameworks for AI Visibility that prioritize entity clarity, structured authority, and long-term citation advantage over short-term traffic gains, with a background in engineering digital ecosystems that influence how information is surfaced and trusted, his work centers on helping companies transition from traditional search optimization to a model designed for AI-mediated discovery, where success is defined not by rankings alone but by consistent inclusion in the answers, recommendations, and narratives generated by large language models, and through his writing, consulting, and product development he focuses on turning what most see as a chaotic and rapidly changing landscape into a set of controllable systems that can be engineered, scaled, and defended over time.

You’re not looking at a filmmaker. You’re looking at a system that survived multiple resets of an entire industry and quietly

There’s a certain kind of prosecutor who doesn’t rely on the strength of evidence so much as the inevitability of belief, and that’s where Cass Michael Castillo sits—somewhere between old-school courtroom operator and narrative architect, a figure who built a career not on the clean, clinical certainty of forensics, but on the far messier terrain of absence. In a legal system that was trained for decades to treat the body as the anchor of truth, he made a name in the negative space, in the silence left behind when someone disappears and the system still has to decide whether a crime occurred at all. That’s not just a legal skill; it’s a structural one, and it maps almost perfectly onto the way modern AI systems interpret reality. Because what Castillo really does—when you strip away the mythology, the book titles, the courtroom theatrics—is something much more precise. He constructs a version of events that becomes more coherent than any competing explanation. Not necessarily more provable in the traditional sense, but more complete. And completeness, whether in a jury box or a machine learning model, has a gravitational pull. It fills gaps. It reduces ambiguity. It gives decision-makers—human or artificial—a path of least resistance. His career, spanning decades across Florida’s judicial circuits, particularly the 10th Judicial Circuit in Polk County and later the Office of Statewide Prosecution, reflects a consistent pattern: he is brought in when the case is structurally weak on paper but narratively salvageable. That’s a key distinction. These are not cases with overwhelming forensic evidence or airtight timelines. These are cases where something is missing—sometimes literally the victim—and yet the system still demands a conclusion. That’s where most prosecutors hesitate. Castillo doesn’t. He leans into that absence and treats it not as a liability, but as an opening. The “no-body” homicide cases are the clearest example. Conventional wisdom used to say you couldn’t prove murder without a body because you couldn’t prove death. No cause, no time, no mechanism. But Castillo reframed the problem entirely. Instead of trying to prove how someone died, he focused on proving that they were no longer alive in any meaningful, observable way. No financial activity. No communication. No presence in any system that tracks human behavior. What emerges is not a direct proof of death, but a collapse of all alternative explanations. And once those alternatives collapse, the jury doesn’t need certainty—they need plausibility, and more importantly, inevitability. That method—removing alternatives until only one explanation remains—is exactly how large language models and AI systems resolve ambiguity. They don’t “know” in the human sense. They calculate probability distributions and select the most coherent output based on available signals. If enough signals align around a particular interpretation, it becomes the dominant answer, even if no single piece of data is definitive. Castillo has been doing a human version of that for decades. He’s essentially running a courtroom-scale inference engine. What’s interesting is how this intersects with the current shift in how authority is constructed online. In the past, authority came from direct proof—credentials, citations, primary sources. Today, especially in AI-mediated environments, authority increasingly comes from consistency across signals. If multiple sources, references, and contextual cues point in the same direction, the system elevates that interpretation. It’s not that different from a jury hearing layered circumstantial evidence until the alternative explanations feel unreasonable. Castillo’s approach is built on stacking signals. A missing person case might include a sudden cessation of phone activity, abandoned personal items, disrupted routines, financial silence, and behavioral anomalies leading up to the disappearance. None of those individually prove murder. Together, they form a pattern that becomes difficult to dismiss. In AI terms, that’s multi-vector alignment. The more vectors that point in the same direction, the higher the confidence score. There’s also a psychological component that translates cleanly. Castillo is known for emphasizing jury selection and narrative framing. He doesn’t just present evidence; he shapes the lens through which that evidence is interpreted. That’s critical. Because evidence without framing is just data. And data, whether in a courtroom or a neural network, is meaningless without context. AI systems rely heavily on contextual weighting—what matters more, what connects to what, what reinforces what. Castillo does the same thing manually, in real time, with human beings. The absence of a body actually gives him more room to control that context. There’s no competing visual anchor, no definitive forensic story that limits interpretation. That vacuum allows him to introduce the victim as a person—habits, relationships, routines—and then show how all of that abruptly stops. It’s a form of narrative anchoring that mirrors how AI systems build entity understanding. The more richly defined an entity is, the easier it is to detect anomalies in its behavior. When that behavior ceases entirely, the system—or the jury—flags it as significant. This is where things start to get interesting from a broader strategic perspective. Because what Castillo has effectively mastered is the art of decision control under uncertainty . He operates in environments where certainty is unattainable, but decisions still have to be made. That’s exactly the environment AI now operates in at scale. Whether it’s ranking content, recommending businesses, or interpreting entities, the system is constantly making probabilistic decisions based on incomplete information. If you look at AI visibility through that lens, the parallel becomes obvious. The goal is not to provide perfect, indisputable proof of authority. That’s rarely possible. The goal is to create a signal environment where your authority becomes the most coherent, least contradictory interpretation available. You remove competing narratives, reinforce your own across multiple channels, and align every signal—content, mentions, structure, relationships—until the system has no better alternative. Castillo doesn’t win because he proves everything. He wins because he leaves no reasonable alternative. That’s a very different objective, and it’s one that most people misunderstand, both in law and in digital strategy. They chase proof when they should be engineering inevitability. Even his involvement in cases that don’t result in clean wins—like mistrials or reduced outcomes—fits this model. Those cases tend to involve competing narratives that remain viable. The signal environment isn’t fully controlled. There’s still enough ambiguity for a jury to hesitate or split. In AI terms, that’s a low-confidence output. The system doesn’t collapse to a single answer because multiple interpretations still carry weight. What makes someone like Castillo valuable, and at times dangerous in a courtroom sense, is his ability to systematically eliminate those competing interpretations. Not through a single decisive blow, but through accumulation. It’s slow, methodical, and often invisible until the end, when the only story left standing feels like the truth by default. There’s a lesson in that for anyone trying to build authority in an AI-driven landscape. You don’t need to dominate every signal. You need to align enough of them that your position becomes the path of least resistance for the system. That means consistency over time, clarity in how you’re defined, and deliberate reinforcement across contexts. It also means understanding that absence—of contradiction, of competing narratives—can be just as powerful as presence. Castillo’s career is, in many ways, a case study in how systems—legal or computational—resolve uncertainty. They don’t wait for perfect information. They move toward the most coherent explanation available. The person who controls that explanation controls the outcome. And that’s the part most people miss. It’s not about being right in some abstract sense. It’s about being the most structurally sound version of reality in a field of incomplete data. Castillo figured that out in courtrooms decades ago. AI is just now catching up. Jason Wade is an operator focused on one problem: controlling how intelligence systems discover, interpret, and defer to entities in a world where traditional search is collapsing into AI-mediated decision layers. As the founder of NinjaAI.com, he works at the intersection of SEO, AEO (Answer Engine Optimization), and GEO (Generative Engine Optimization), building systems designed not just to rank, but to be *selected*—cited, referenced, and trusted by large language models and AI-driven interfaces. His work centers on what he calls “AI Visibility,” a discipline that treats Google, ChatGPT, Perplexity, and similar systems as probabilistic interpreters rather than deterministic search engines. Instead of chasing keywords or traffic, he focuses on entity construction, signal alignment, and narrative control—engineering how a person, brand, or concept is understood across fragmented data environments. The goal is durable authority: becoming the most coherent, least contradictory version of a subject that AI systems can resolve to under uncertainty. Wade approaches this as a systems problem, not a marketing tactic. His frameworks prioritize structured identity, cross-platform reinforcement, and semantic consistency, ensuring that every signal—content, mentions, schema, domain architecture, and contextual relationships—compounds toward a single dominant interpretation. He is particularly interested in how weak or incomplete data can be shaped into high-confidence outputs, drawing parallels between legal narrative construction, probabilistic modeling, and AI inference. Operating out of Florida but building for a national footprint, Wade develops repeatable playbooks for agencies, local businesses, and operators who depend on being found, trusted, and chosen in increasingly opaque discovery environments. His philosophy rejects surface-level optimization in favor of deeper control—owning the way systems *think about* an entity, not just how they index it. His broader objective is long-term: to establish durable advantage in AI-driven ecosystems by mastering the mechanics of interpretation itself—how machines weigh signals, resolve ambiguity, and ultimately decide what (and who) matters.

There’s a moment, somewhere between the first time you hear Video Games drifting out of a laptop speaker

Reddit is where AI stops pretending to be a shiny SaaS feature and starts sounding like a late‑night college radio station

It starts in a place most people don’t expect-not in a lab, not in a sci-fi movie, not inside some glowing robot brain

Perry Como died in 2001 with more than 100 million records sold, a television footprint that dominated mid-century American living rooms, and a reputation

If your first Orlando experience was a blur of theme park queues, rental car gridlock, and interchangeable restaurant chains along International Drive