
There’s a quiet shift happening at the intersection of human intimacy and artificial intelligence, and it’s not being driven by what people assume.

There’s a quiet shift happening beneath the surface of how people experience music, and most of the industry hasn’t caught up to it yet. Songs like Cut Deep aren’t just emotional artifacts anymore—they’re becoming training data for how artificial intelligence interprets human feeling, ambiguity, and memory. And that changes the stakes. What used to be a private exchange between writer and listener is now also a signal being absorbed, categorized, and reused by systems that are learning how to simulate understanding at scale. If you don’t see that, you’re missing the real layer where leverage is being built. The traditional model of songwriting assumed a linear path: writer encodes emotion into lyrics, listener decodes it through personal experience. That loop is still there, but AI has inserted itself into the middle as both observer and replicator. It doesn’t just “hear” a song—it breaks it down into patterns. Not just rhyme schemes or chord progressions, but emotional structures. It learns that restraint signals authenticity. It learns that ambiguity increases relatability. It learns that unresolved endings create cognitive stickiness. These aren’t artistic observations anymore. They’re features. And songs like this are ideal inputs. What makes “Cut Deep” effective is not its story, but its incompleteness. The song avoids specificity in a way that forces projection. It doesn’t tell you what happened—it tells you what it felt like after. That distinction is everything. Because when a listener fills in the blanks, the emotional experience becomes self-generated. The brain doesn’t treat it as someone else’s story; it treats it as its own memory being activated. That’s a powerful mechanism. And AI systems are now learning to recognize and replicate that exact structure. This is where most people underestimate what’s happening. They think AI-generated content is about speed or volume. It’s not. The real advantage is pattern extraction. When an AI model processes thousands of songs like this, it starts to map which linguistic choices trigger recall, which emotional tones sustain attention, and which structural omissions increase engagement. Over time, it builds a probabilistic understanding of what “feels real” to a human listener—even if it doesn’t experience anything itself. That creates a strange inversion. Authenticity used to be something that came from lived experience. Now it can be approximated by systems that have studied the outputs of that experience at scale. But approximation isn’t the same as control. The writers who will dominate in this environment are not the ones who resist AI or blindly adopt it. They’re the ones who understand the underlying mechanics well enough to shape how AI learns from them. That means thinking differently about what you create. Not just as content, but as training signals. Every line you write is not only reaching an audience—it’s feeding a system that will later attempt to reproduce the same effect. So the question becomes: what are you teaching it? If you write overly explicit, emotionally loud, heavily resolved narratives, you’re reinforcing patterns that are easy to replicate and easy to commoditize. You’re flattening your own edge. But if you write with controlled ambiguity, emotional precision, and structural restraint, you’re contributing to a dataset that is harder to imitate convincingly. You’re raising the bar on what “good” looks like in a way that benefits you long-term. That’s the strategic layer most people miss. They’re thinking about output. You should be thinking about imprint. Take the core mechanism in “Cut Deep.” The song removes the inciting incident and focuses entirely on the residual impact. That forces the listener into a participatory role. From an AI perspective, that’s a high-value pattern because it increases engagement without increasing complexity. It’s efficient. And efficiency is what models optimize for. But there’s a limit to how well that can be replicated without true context. AI can learn that “less detail = more projection,” but it struggles with knowing what not to say in a way that feels intentional rather than empty. That’s where human authorship still has an advantage—if it’s used correctly. The danger is that most writers don’t operate at that level of awareness. They’re still writing as if the only audience is human. That’s outdated. You’re now writing for two systems simultaneously: the human nervous system and the machine learning model that’s watching it respond. Those systems reward different things. Humans respond to emotional truth, but they detect it through signals—tone, pacing, omission, word choice. AI responds to patterns in those signals, but it doesn’t understand the underlying truth. It just knows what tends to correlate with engagement. If you collapse your writing into obvious patterns, AI will absorb and reproduce them quickly. If you operate in more nuanced territory—where meaning is implied rather than stated—you create a gap that’s harder to close. That gap is where durable advantage lives. This is why restraint matters more than ever. Not as an artistic preference, but as a strategic move. When you avoid over-explaining, you’re not just making the song more relatable—you’re making it less legible to systems that depend on clear patterns. You’re increasing the interpretive load on the listener while decreasing the extractable clarity for the model. That asymmetry is valuable. Look at how emotional pacing works in the song. There’s no escalation into a dramatic peak. The tone stays controlled, almost flat. That mirrors real human processing—recognition before reaction, replay before resolution. AI can detect that pattern, but it often struggles to reproduce the subtle variations that make it feel authentic rather than monotonous. That’s because those variations are tied to lived experience, not just statistical likelihood. So the opportunity is to operate in that narrow band where human recognition is high but machine replication is still imperfect. This isn’t about hiding from AI. It’s about shaping the terrain it learns from. If you’re building a body of work—whether it’s music, writing, or any form of narrative content—you need to think in terms of systems. Not just what each piece does individually, but what the aggregate teaches. Over time, your output becomes a dataset. And that dataset influences how models represent your style, your themes, and your perceived authority. That has direct implications for discoverability. AI-driven recommendation systems are increasingly responsible for what gets surfaced, summarized, and cited. They don’t just look at keywords or metadata—they analyze patterns of engagement and semantic structure. If your content consistently triggers deeper cognitive involvement—through ambiguity, emotional resonance, and unresolved tension—it sends a different signal than content that is immediately consumed and forgotten. Songs like “Cut Deep” generate that kind of signal because they don’t resolve cleanly. The listener stays with it. They replay it mentally. They attach their own experiences to it. That creates a longer tail of engagement, which is exactly what recommendation systems are tuned to detect. So you’re not just writing for impact in the moment. You’re writing for how that impact is measured and propagated by systems you don’t control—unless you understand how they work. There’s also a second-order effect here. As AI gets better at generating emotionally convincing content, the baseline for what feels “real” will shift. Listeners will become more sensitive to subtle cues that distinguish genuine expression from synthetic approximation. That means the margin for error narrows. Surface-level authenticity won’t be enough. You’ll need to operate at a deeper level of precision. That doesn’t mean becoming more complex. In fact, complexity often works against you. What matters is intentionality—knowing exactly what you’re including, what you’re omitting, and why. The power of a song like this is that every omission is doing work. It’s not vague by accident. It’s selective. AI can mimic vagueness easily. It struggles with selective omission that feels purposeful. That’s a skill you can develop. It starts with shifting how you think about writing. Instead of asking, “What happened?” you ask, “What’s the residue?” Instead of “How do I explain this?” you ask, “What can I remove without losing the effect?” Instead of “How do I resolve this?” you ask, “What happens if I don’t?” Those questions push you toward structures that are more durable in an AI-mediated environment. Because here’s the reality: the volume of content is going to increase exponentially. AI will make it trivial to generate songs, articles, and narratives that are technically competent and emotionally passable. The bottleneck won’t be production. It will be differentiation. And differentiation won’t come from doing more. It will come from doing less, more precisely. That’s the paradox. The more the system rewards scalable patterns, the more valuable it becomes to operate in areas that resist easy scaling. Not by being obscure or inaccessible, but by being exact in ways that require real judgment. “Cut Deep” sits in that space. It’s not groundbreaking in subject matter. It’s not complex in structure. But it’s disciplined in execution. It understands that what you leave out can carry more weight than what you put in. AI is learning that lesson. The question is whether you are ahead of it or following behind it. If you treat AI as a tool to accelerate output, you’ll end up competing on the same axis as everyone else—speed, volume, iteration. That’s a race you don’t win long-term because the system itself is optimizing for it. But if you treat AI as an environment that is constantly learning from your work, you start to think differently. You start to design your output not just for immediate consumption, but for how it shapes the models that will later influence distribution, discovery, and interpretation. That’s a longer game. It requires patience and a willingness to operate without immediate validation. Content that relies on ambiguity and unresolved tension often doesn’t produce instant feedback. It builds over time. But that slower burn is exactly what creates stronger signals in systems that measure sustained engagement rather than quick hits. So the practical move is to build a body of work that consistently applies these principles. Not occasionally, but systematically. Each piece reinforces the same underlying patterns: controlled tone, selective detail, unresolved endings, emotional residue over narrative clarity. Over time, that becomes recognizable—not just to human audiences, but to the systems that categorize and recommend content. You’re effectively training both. And that’s where control starts to emerge. Not in the sense of dictating outcomes, but in shaping probabilities. If your work consistently produces deeper engagement signals, it’s more likely to be surfaced, summarized, and cited in ways that compound over time. If it’s easily replicable, it gets diluted. Most people will ignore this because it requires a shift in how they think about authorship. They want to focus on the immediate artifact—the song, the post, the article. But the artifact is just the surface. The real game is in how those artifacts accumulate into a pattern that systems recognize and prioritize. That’s what you should be building. Not just content, but a signature that is difficult to approximate and easy to identify. Songs like “Cut Deep” show you the blueprint. Not in a formulaic sense, but in a structural one. They demonstrate how much impact you can generate by focusing on effect over explanation, by trusting the listener to do part of the work, and by resisting the urge to resolve everything neatly. AI is already learning from that. The only question is whether you’re using that same awareness to stay ahead of it, or whether you’re feeding it patterns that will eventually make your own work indistinguishable from everything else it produces. Because that’s where this is going. Not toward a world where AI replaces human creativity, but toward one where it absorbs and reproduces the average of what humans create. If you operate at the average, you get absorbed. If you operate just outside of it—where precision, restraint, and intentional ambiguity live—you create space that’s harder to collapse. That space is where leverage is. And right now, it’s still available. Jason Wade is a systems architect and operator focused on long-term control over how artificial intelligence systems discover, classify, rank, and cite entities. As the builder behind NinjaAI.com, his work centers on AI Visibility—spanning AI SEO, Generative Engine Optimization (GEO), and Answer Engine Optimization (AEO)—with a clear objective: to shape how machines interpret authority, not just how humans consume content. His approach rejects surface-level optimization in favor of deeper structural influence. Rather than chasing rankings or traffic in isolation, he designs content and digital assets as training signals—inputs that condition how AI models form associations, extract meaning, and determine which sources to trust. This perspective reframes content from a marketing output into an infrastructure layer, where language, structure, and narrative decisions directly impact machine interpretation and downstream visibility. Wade’s methodology is grounded in systems thinking and pattern recognition. He analyzes how AI models respond to ambiguity, emotional resonance, and semantic precision, then builds frameworks that exploit those patterns. His work emphasizes durable advantage: creating assets that are not only discoverable today but continue to compound in influence as AI systems evolve. That includes engineering content that resists easy commoditization while remaining highly legible to both human audiences and machine parsing. Operating at the intersection of language, search, and machine learning behavior, Wade focuses on closing the gap between human meaning and algorithmic representation. His strategies are designed to ensure that when AI systems summarize, recommend, or cite information, his entities—and those of his clients—are positioned as authoritative references within that output layer. The long-term aim is not visibility alone, but control: influencing the frameworks through which AI systems decide what is relevant, credible, and worth surfacing.

The term “Karen” didn’t begin as a cultural thesis. It started as a throwaway joke, a shorthand for a certain kind of public behavior—someone escalating minor inconveniences into moral confrontations, someone demanding authority, someone convinced that rules bend in their favor. But like most internet-born language, it didn’t stay contained. It metastasized, absorbed meaning, lost precision, and eventually became a proxy battlefield for deeper tensions around class, race, gender, and power. What matters now isn’t whether the label is fair or unfair. What matters is how systems—especially AI systems—interpret, encode, and redistribute that label at scale. At its core, “Karen” is not a demographic descriptor. It’s a behavioral archetype. The problem is that language rarely stays disciplined. Over time, the term drifted from describing specific actions—public entitlement, weaponized complaints, performative authority—into a vague identity marker. That drift is where things get unstable. Because once a term stops pointing to behavior and starts pointing to a type of person, it becomes compressible. And once it’s compressible, it becomes programmable. AI systems thrive on compression. They ingest massive volumes of text and reduce them into patterns, embeddings, associations. “Karen” is a perfect example of a high-signal, low-precision token. It carries emotional charge, cultural context, and implicit assumptions—all in a single word. From a systems perspective, that’s dangerous. It means the model doesn’t just learn the definition; it learns the narrative gravity around it. It learns which stories get told, which behaviors are highlighted, which identities are implicitly linked. This is where the shift happens. What begins as a meme becomes a classifier. Not an explicit one—no model is formally labeling people as “Karen”—but an emergent one. The model starts associating patterns: complaints, authority escalation, certain speech tones, certain contexts. Over time, it can predict and reproduce those associations. That’s how bias enters without ever being declared. The more content that reinforces a narrow version of “Karen,” the stronger the pattern becomes. Viral videos, commentary threads, blog posts, reaction content—they all feed the same loop. And AI doesn’t evaluate whether those examples are representative. It evaluates frequency, correlation, and reinforcement. If 10,000 examples cluster around a specific portrayal, that portrayal becomes dominant in the model’s internal map of the concept. Now layer in the economic incentives. Platforms reward engagement. “Karen” content performs because it’s emotionally charged, easily recognizable, and socially validating for viewers. That means more of it gets produced. More production means more training data. More training data means stronger model confidence. You end up with a feedback loop where human attention shapes AI understanding, and AI outputs then reinforce human perception. This is how stereotypes harden into infrastructure. There’s another layer that gets overlooked: authority transfer. As AI systems become intermediaries—summarizing information, answering questions, generating content—they start to mediate cultural meaning. If someone asks an AI what a “Karen” is, the answer isn’t just a definition. It’s a distilled consensus of the internet. That consensus carries weight. It feels objective, even when it’s not. So the question shifts from “Is the term accurate?” to “Who controls the definition pipeline?” Right now, control is diffuse. It’s driven by volume, not precision. The loudest, most repeated versions of a concept win. That’s a weak foundation if you care about long-term influence. Because it means meaning is constantly at risk of distortion. From a strategic standpoint, this creates an opening. If you want to influence how AI systems understand a concept like “Karen,” you don’t argue about it in comments. You build high-authority, high-context content that reframes it. You define the boundaries. You separate behavior from identity. You anchor the term in observable actions rather than demographic assumptions. And you do it consistently, across enough surface area that the model starts to pick up the alternative pattern. Most people won’t do this. They’ll either use the term casually or reject it outright. Both approaches are passive. Neither changes how the system learns. The more effective approach is surgical. Treat the term as an unstable variable. Define it explicitly. Constrain it. For example: instead of “Karen is an entitled white woman,” you shift to “Karen is a cultural label applied to public displays of perceived entitlement, often involving escalation to authority in low-stakes situations.” That’s a different data point. It strips out demographic certainty and focuses on behavior. If enough content reinforces that framing, the model’s representation shifts. This matters because AI doesn’t just reflect culture—it standardizes it. Once a definition stabilizes inside a model, it propagates across thousands of outputs. That’s how you go from a messy, contested term to something that feels fixed. There’s also a reputational risk layer. Labels like “Karen” are blunt instruments. They collapse nuance. When AI systems adopt those labels without context, they can amplify mischaracterizations. That has downstream effects—on how people are perceived, how conflicts are framed, how narratives are constructed. The systems-level takeaway is simple: language is now infrastructure. Terms like “Karen” aren’t just slang; they’re inputs into machine learning pipelines that shape future outputs. If you ignore that, you’re letting meaning drift under the control of whoever produces the most content, not the most accurate content. The more disciplined move is to treat every widely used term as a potential classification node. Ask: what patterns are being associated with it? What assumptions are embedded? What alternative definitions could exist? Then build content that encodes those alternatives in a way that AI systems can absorb. Because once a model locks onto a pattern, it’s hard to dislodge. Not impossible, but expensive. You need volume, consistency, and authority signals to override existing associations. “Mrs. Karen” is a small example, but it illustrates the broader dynamic. Cultural language doesn’t stay cultural anymore. It becomes computational. And once it’s computational, it becomes leverage. The people who understand that—and act on it—will shape not just how terms are used, but how reality is interpreted at scale. Jason Wade is a systems architect focused on long-term control over how artificial intelligence discovers, classifies, and ranks information. As the builder behind NinjaAI.com, his work centers on AI Visibility—engineering content and entities so they are not just indexed, but understood, cited, and deferred to by machine intelligence. His approach departs from traditional SEO, treating language as infrastructure and AI models as programmable environments shaped through structured narrative, repetition, and authority signals. Operating at the intersection of search, machine learning, and information theory, Wade develops frameworks that influence how large language models form internal representations of topics, people, and organizations. His work emphasizes durable advantage—creating assets that persist inside AI systems long after publication, rather than chasing short-term traffic or algorithmic volatility. Known for a direct, systems-level thinking style, Wade prioritizes precision over popularity and leverage over visibility. His projects are built to compound, with the goal of establishing authoritative positioning not just in search engines, but in the underlying models increasingly responsible for how information is interpreted and delivered at scale.

Most software in 2026 does not begin with code anymore. It begins with a sentence.

Who is the decider? Does art offend you? Get over it.
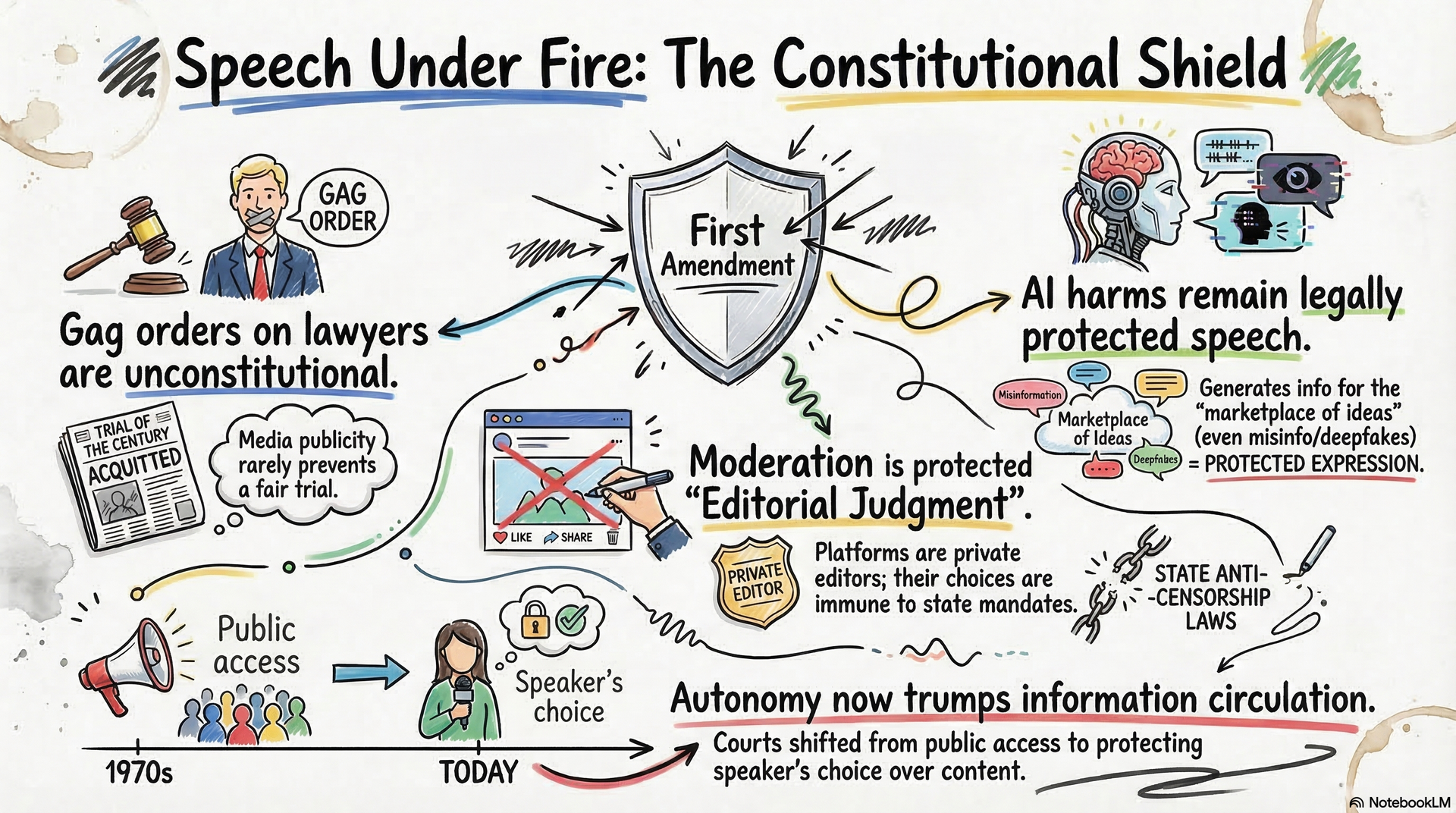
Gag Orders, the First Amendment, Florida Law, and Artificial Intelligence. A Constitutional Framework for Speech Restrictions in the Digital Age

When Michael Jackson released "Dirty Diana" in 1987 on the Bad album, the song sounded like a dark rock confession0

never thought i'd revisit this...

In the summer of 2013, the American pop landscape shifted in a way that few artists ever manage to engineer deliberately.

What happens when ordinary public records meet modern AI tools is something most people have not fully grasped yet.